
今天凌晨,微软在官网发布了创新小参数模型Mu。
Mu仅有3.3亿参数,但其性能可以比肩微软之前发布的小参数模型Phi-3.5-mini,体量却比它小10倍左右,并且在离线NPU的笔记本设备上,可以跑出每秒超过100 tokens的响应,这在小参数模型领域非常罕见。
此外,Mu支持在Windows中设置智能体,可将自然语言指令实时转化为系统操作,例如,只需对着电脑说一句 “把鼠标指针调大一些,调整屏幕亮度”,智能体就能精准定位到相关设置项一键完成调整。
Mu架构简单介绍
Mu借鉴了之前微软发布的小参数模型Phi Silica,专为小型本地部署优化,尤其是在配备NPU的Copilot+ PC上。
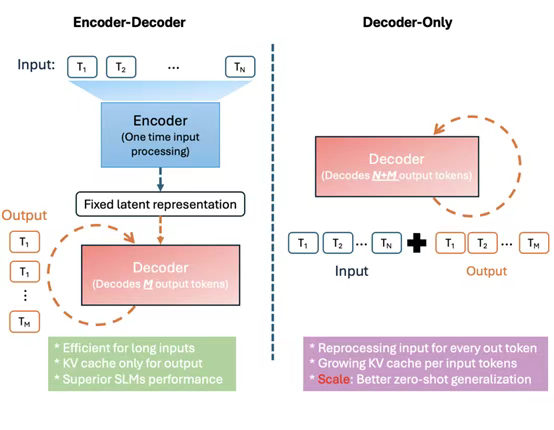
架构方面,Mu使用了仅解码器的Transformer,并在此基础之上进行了双重层归一化、旋转位置嵌入和分组查询注意力三大创新。
双重层归一化方法通过在Transformer架构的每个子层前后分别实施LayerNorm操作,有效确保了激活值的分布具有良好的统计特性,从而显著增强了训练过程的稳定性。
不仅避免了深层网络中常见的训练不稳定问题,还通过减少数值不稳定情况的发生,间接提高了训练效率,从总体上降低了训练时间和资源消耗。
在Transformer架构中,位置嵌入是让模型理解序列顺序的关键部分。传统的绝对位置嵌入方法是给每个固定位置分配独立的向量,把绝对位置信息添加到词向量中。
但这种方式有两个根本问题:一是当输入序列长度超过训练时的长度,模型因为没有对应位置的预训练向量,就很难准确理解超出部分的位置关系;
另外一个是绝对位置编码只能反映 token 在序列里的绝对位置,没办法直接表示 token 之间的相对距离,在需要理解长距离关系,例如,分析长句语法、代码函数调用顺序的任务中,存在天然不足。
旋转位置嵌入则通过引入复数域的旋转操作,从本质上改变了位置编码的机制。其核心原理基于复数乘法的几何特点,把每个位置的嵌入向量表示成复数形式,通过和旋转矩阵相乘,让向量在复平面上旋转。

对于每个位置和维度,旋转位置嵌入都定义了旋转矩阵,当输入序列中的两个 token 交互时,它们位置嵌入向量的旋转角度差异,直接体现了两者的相对距离。从数学角度看,旋转位置嵌入 把位置编码变成了动态可扩展的函数映射,而不是静态的向量存储。这一特性让模型具备了出色的长序列外推能力。
在推理时遇到超长序列,旋转位置嵌入 可以根据已经学习到的旋转规则,动态生成超出训练长度部分的位置编码,避免了传统绝对位置编码因为 没见过的位置而导致性能大幅下降的问题。
Mu还使用了分组查询注意力对多头注意力机制进行了大量优化。在传统的多头注意力中,每个头都拥有自己的Key、Query和Value矩阵,这导致了大量的参数和内存消耗。
分组查询注意力则通过在头组之间共享键和值,显著减少了注意力参数的数量和内存占用。例如,如果有12个头,可以分为3组,每组4个头共享相同的键和值。
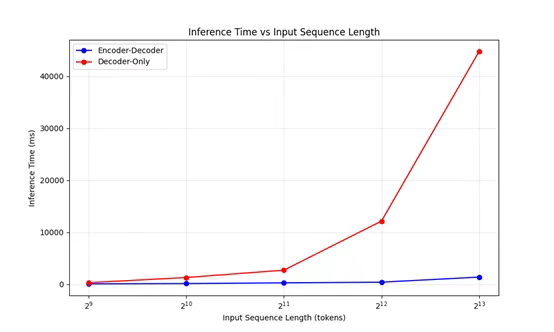
这种设计不仅减少了参数和内存占用,降低了在NPU上的延迟和功耗,提高了模型的运行效率,还通过保持头的多样性,确保了每个头可以独立计算查询,从而维持了与传统多头注意力机制相当的性能。
此外,Mu还使用了预热稳定衰减时间表和Muon优化器等训练技术来进一步优化其性能。微软使用了A100 GPU对Mu进行了训练,遵循Phi模型开发中首创的技术,首先在数百亿个最高质量的教育token上进行预训练,以学习语言的语法、语义和一些世界知识。
为了进一步提高准确性,还从Phi模型中进行知识蒸馏。通过捕获Phi模型的一些知识,Mu模型实现了显著的参数效率。其参数只有Phi-3.5-mini的十分之一,性能却和它差不多。
支持Windows智能体
为提升 Windows 系统的易用性,微软一直着力攻克修改数百项系统设置的难题,目标是在“设置”中打造一个理解自然语言并能无缝修改可撤销相关设置的 AI 智能体。微软计划将该智能体集成到现有搜索框中,以实现流畅的用户体验,这要求对众多可能的设置实现超低延迟响应。
在测试了各种模型后,Phi LoRA 最初达到了精度目标,但规模过大,无法满足延迟要求。Mu具有合适的特性,需要针对特定任务进行调整才能在 Windows设置中实现最佳性能。
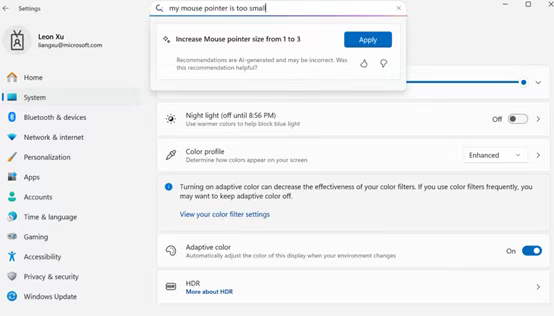
此场景下的基线 Mu 模型虽在性能和功耗方面表现出色,但在使用相同数据且未经任何微调时,精准度会下降50%。为缩小这一差距,微软将训练规模扩大到 360万个样本,提升了 1300 倍,并将处理的设置从约50项扩展至数百项。
通过采用自动化标注的合成方法、带元数据的提示调优、多样化措辞、噪声注入和智能采样,用于设置智能体的Mu微调模型成功达成质量目标。Mu微调模型的响应时间控制在 500 毫秒以内。根据测试显示,Mu模型打造的智能体,在Windows设置的理解、执行操作方面比较出色。
本文素材来源微软,如有侵权请联系删除






