全球承载20%互联网流量的云安全巨头Cloudflare,于周二正式启动一项名为“按爬行付费”(Pay per Crawl)的实验性市场,首次为网站所有者与
AI公司之间的内容交易提供了可编程的基础设施。这一举措不仅可能颠覆传统网络爬虫的“免费采集”模式,更试图为深陷流量危机与版权纠纷的出版行业开辟一条新的生存路径。
过去一年中,AI大模型的爆发式增长引发了数据采集的“军备竞赛”。OpenAI的GPT-4、谷歌的Gemini等模型训练需要海量网页数据,导致AI爬虫对新闻网站、博客等平台的抓取频率激增。Cloudflare的数据揭示了这一趋势的极端性:2024年6月,其网络监测显示,OpenAI的爬虫每产生一次用户推荐需抓取网站1700次,而Anthropic的Claude模型这一数字高达7.3万次——相比之下,谷歌搜索引擎爬虫的对应比例仅为14:1。
这种“高耗能、低回报”的抓取模式,直接冲击了依赖搜索引擎流量的出版商。传统模式下,出版商允许谷歌等搜索引擎免费抓取内容,以换取搜索结果中的曝光和广告收入。然而,AI聊天机器人的崛起正在瓦解这一生态:用户越来越多地通过ChatGPT、Perplexity等工具直接获取信息摘要,而非点击链接访问原文。Cloudflare CEO马修·普林斯(Matthew Prince)直言:“AI公司正在用出版商的内容训练模型,然后抢走他们的读者——这是一场零和游戏。”
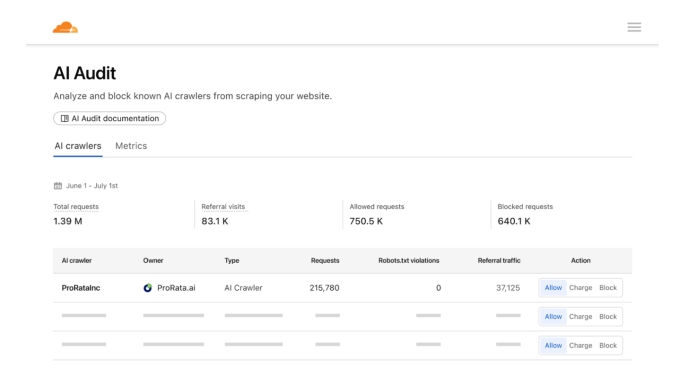

为应对挑战,Cloudflare早在2023年便为出版商推出了一系列防御工具,包括一键屏蔽所有AI爬虫的“机器人防火墙”,以及实时监控爬虫行为的仪表盘。但普林斯在2024年接受TechCrunch采访时透露,这些产品只是过渡方案:“我们的终极目标是建立一个市场,让出版商能像出售数字广告一样,向AI公司分发内容并获得报酬。”如今,这一愿景正变为现实。
Cloudflare的新市场引入了“按次计费”的微交易模型。参与私有测试的网站所有者可通过Cloudflare仪表盘设置三种权限:
-
- 付费抓取:为AI爬虫设定每次访问的费率(如每千次爬取收费0.1美元);
Cloudflare的技术能精准识别爬虫用途——无论是用于训练大模型、填充AI搜索结果,还是生成聊天机器人回复,网站主均可通过数据看板追踪内容流向。例如,一家新闻网站可选择仅对用于“AI搜索响应”的爬取收费,而对学术研究用途开放免费访问。
这一模式的底层支持来自Cloudflare的全球边缘网络。作为全球第二大CDN提供商,Cloudflare的服务器分布在300多个城市,可实时拦截或放行爬虫请求,并在网络边缘完成微支付结算,避免高额跨境交易费用。公司发言人表示,目前市场仅支持法定货币结算,但普林斯在TBPN节目中透露,正在探索稳定币支付方案,甚至可能发行自有稳定币以降低交易成本。
Cloudflare的市场推出时机,恰逢出版行业面临“AI生存危机”。一方面,传统流量入口萎缩:谷歌搜索占新闻网站流量的比例从2020年的40%降至2024年的25%,而ChatGPT等工具的引用几乎不带来点击;另一方面,版权诉讼进展缓慢:《纽约时报》虽于2023年起诉OpenAI和微软,但案件可能持续数年,且赔偿金额存在不确定性。
在此背景下,部分出版商已转向许可协议。例如,美联社与OpenAI达成多年合作,允许其使用新闻档案训练模型;康泰纳仕(Condé Nast)则与谷歌签订协议,确保其内容出现在AI搜索结果中。然而,这些交易仅限于头部玩家,中小出版商仍被排除在外。Cloudflare的市场试图通过去中心化降低门槛:任何使用Cloudflare服务的网站均可参与,无需单独谈判。
不过,AI公司是否愿意为已习惯免费获取的数据付费?普林斯承认:“说服他们改变行为模式需要时间。”不过,他指出,欧盟《AI法案》等监管压力正在上升,未来AI公司可能被迫使用合规数据源。此外,市场初期将采用“双向选择”机制:AI公司需主动注册并设置预算,出版商则可筛选合作方,避免“垃圾爬虫”干扰。
Cloudflare的野心不止于微支付,其在博客中描绘了一个更宏大的愿景:在AI代理主导的未来,用户可授权智能助手(如ChatGPT插件)代表自己访问网站、合成信息,并自动从预算中扣费。例如,用户可要求AI助手“用5美元合成最新癌症研究报告”,代理将根据出版商的定价自动购买内容,全程无需人工干预。
这一场景依赖“可编程货币”与“边缘计算”的结合。Cloudflare的边缘服务器可充当“智能合约执行器”,在数据离开网站前完成授权验证与支付结算,确保出版商即时获益。普林斯比喻道:“这就像在网络传输层嵌入了一个‘数字收银台’,每次内容传递都是一次交易。”
但很明显,这一愿景的实现阻碍还是非常多的,技术层面,需解决微支付的高频结算与低手续费矛盾;商业层面,需平衡出版商定价权与AI公司成本承受力;监管层面,则需应对反垄断与数据隐私审查。普林斯坦言:“我们可能成为行业公敌,但总得有人迈出第一步。”
目前,已有康泰纳仕、时代杂志、美联社等数十家头部出版商加入测试,覆盖全球超10亿月活用户。若市场成功,Cloudflare不仅可收取交易佣金,还能巩固其作为“网络中立基础设施”的地位——在AI与出版商的博弈中,成为不可或缺的第三方。
数据标注平台Scale AI、版权管理公司Copyright Clearance Center等均已布局AI数据交易,而谷歌、亚马逊等云巨头也可能推出类似服务。
普林斯强调,Cloudflare的优势在于“中立性”:“我们不训练模型,也不销售内容,我们的唯一利益是让交易透明化。”
对于出版行业而言,Cloudflare的实验或许是一场“豪赌”。但正如《大西洋月刊》CEO尼古拉斯·汤普森所言:“在AI吞噬一切的时代,被动防御已不够——我们必须重新定义内容价值,哪怕这意味着颠覆自己。”而Cloudflare的市场,正是这场自我革命的第一块试验田。
从“免费抓取”到“按需付费”,Cloudflare的市场标志着AI时代内容经济的一次范式转移。尽管前路充满不确定性,但其尝试揭示了一个真理:在数据成为新石油的时代,控制权终将回归创造者手中。无论是出版商、AI公司,还是普通用户,都将在这场变革中重新定义自己的角色——而Cloudflare,正试图成为那个书写规则的人。